
引言
在十月中旬,我参加了由 OceanBase 举办的为期半个多月的数据库大赛,这已经是我第二次参加数据库内核类的比赛了,然而这次是第一次认真对待,并且我花了大量的时间在这上面——日均 8 小时。不得不说,这是一个非常能让人“上瘾”的比赛 orz。有时候,在熟悉代码、debug 的时候,不知不觉 2 个小时就过去了。
虽然最后在我和另一个队友的努力下差一点杀入决赛(再另外一个队友尚处学习阶段),但是还是学到了不少的东西。最后在全国获得 61/1154 的成绩。争取明年拿下决赛!
我想在这里记录一下我参加这个比赛的实现思路,来让自己真正有所收获,也希望能给大家一些思路和启发。包括但不限于:
- 数据库的基本实现思想
- update
- simple-sub-query
- order-by
- complex-sub-query
- create-table-select
- date
数据库的基本实现思想
可能有同学会好奇,数据库不就是一个存数据的东西嘛,把数据存到磁盘里面不就行了?
1 | import os |
事实上,我刚开始了解数据库的时候也有这个想法,一个 txt 格式的文件就搞定了嘛,实在不行,咱就分成多个文件。不过咱们仔细想想,数据库是支持很多数据类型的,比如 int、date、boolean 等等。如果全基于字符串存在文本文件里,势必造成很大的转换开销。此外,还有锁机制、更新数据、事务等等功能,如果仅靠一个简单的 txt 格式的文件,虽然最终可以实现,但终究不够优雅,且性能 = 💩。
那经典的数据库系统是怎么存、取数据的?
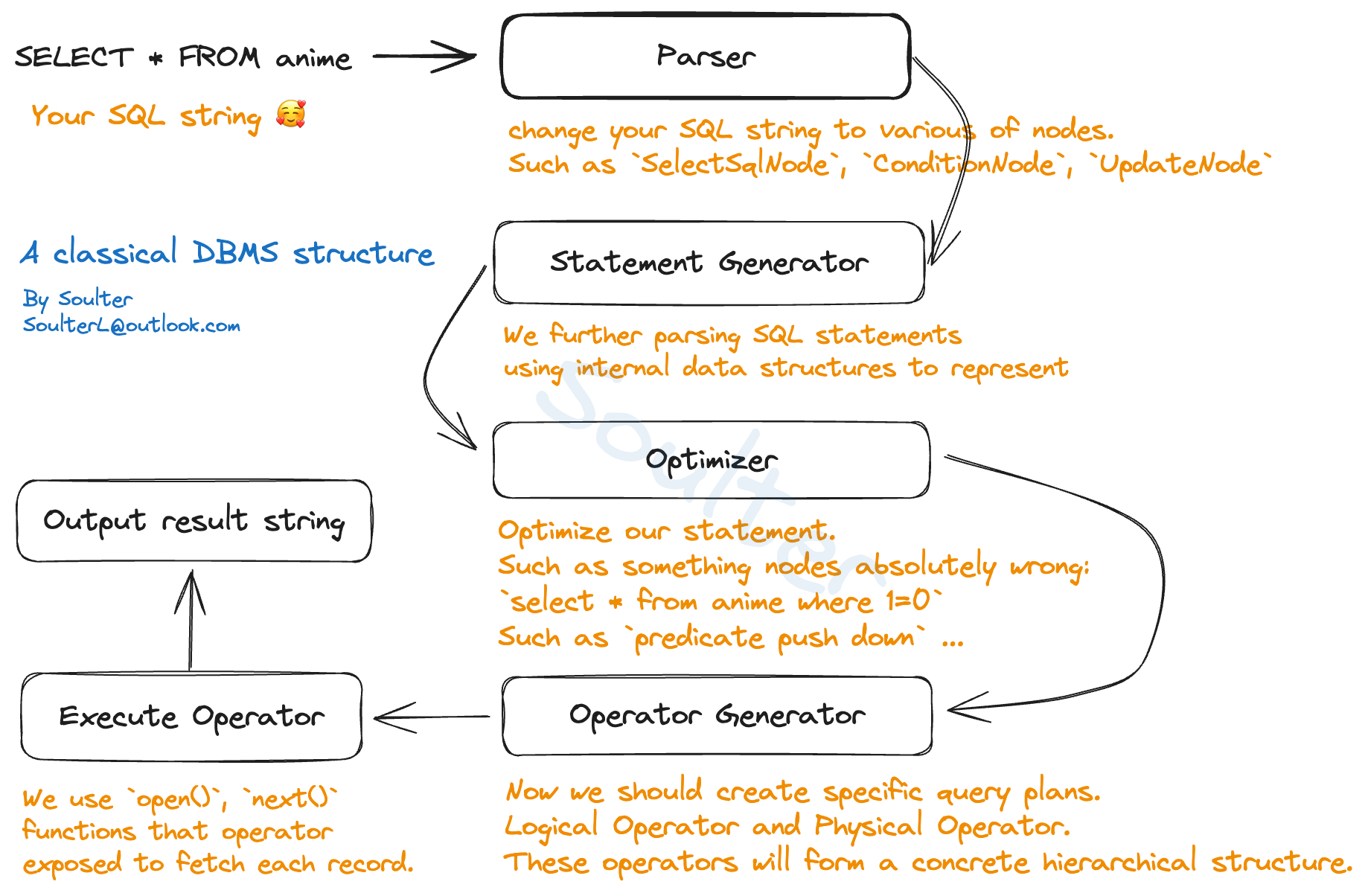
当我们发送一个 SQL 请求到数据库中,首先,数据库系统会将 SQL 字符串进行解析,生成抽象语法树(AST),这一步会将 SQL 语句的每个部分解析成不同的 Nodes。
例如,我们请求: select * from tb where id=1;,解析得到的 node 如下:
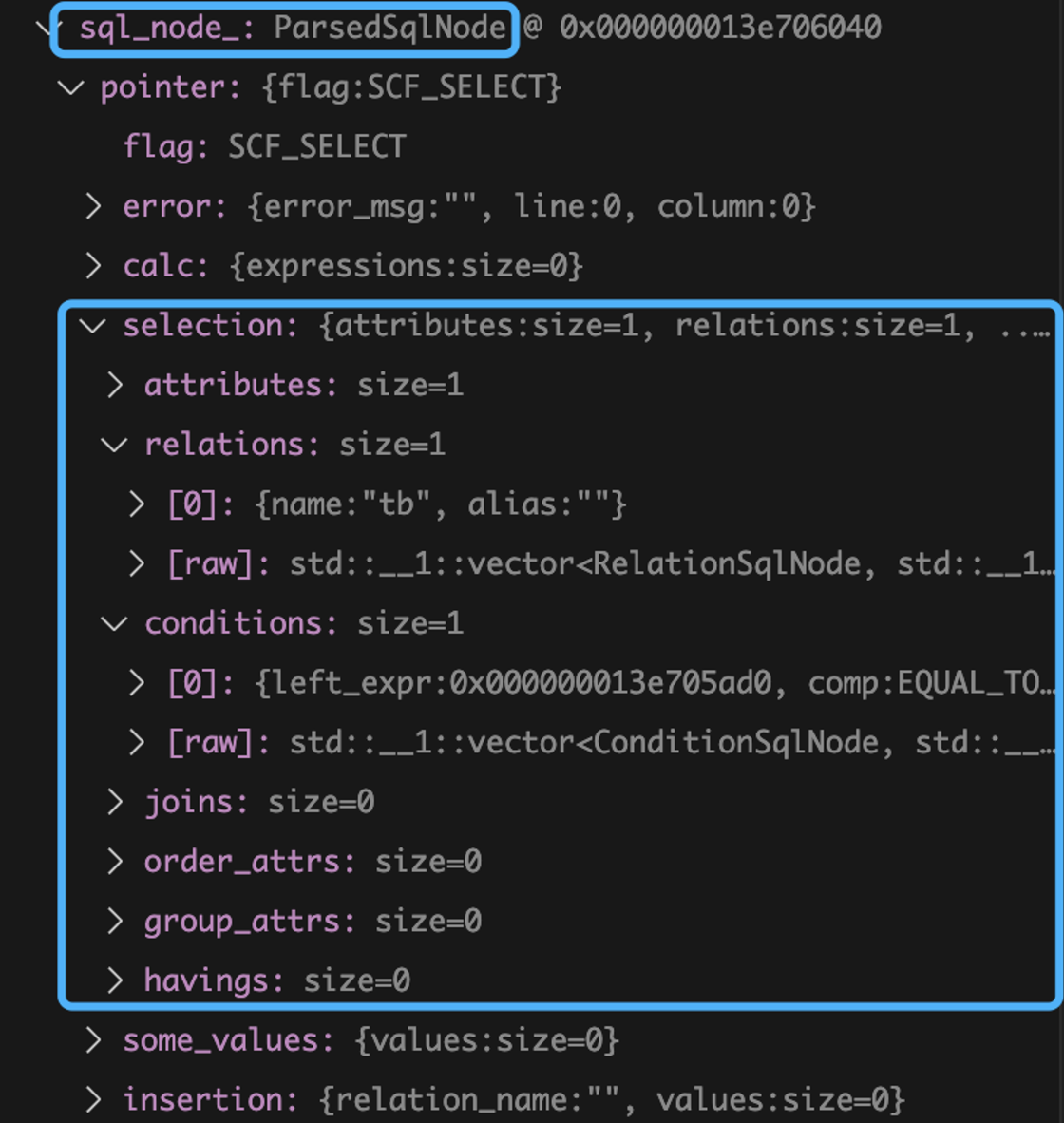
然后再将这些 node 进一步解析成 Statement。这里大家可能会不解,为什么还要单独生成一个 Statement,明明 node 看起来就很直观了。当我们生成好 Statement 后,其内会有要查询的表的对象实例、conditions 得到的 Filter Statement(用于过滤 Record) 、表达式等等。简明说,就是进一步抽象,让我们能够再在后面的流程中更方便地使用。
然后就到了生成算子的部分了。这也是流程中的一大难点。
算子分为逻辑算子和物理算子。并且都细分为删除算子、投影算子、过滤算子、Join算子、更新算子、线性扫描算子、索引扫描算子等等。逻辑算子相当于搭好一个外层框架,以供优化(谓词下推、fast-fail等等优化算法)使用。后者根据前者中存的内容生成具体的执行计划,比如我们有一个 Select 请求:select * from tb where id=1。最终生成的物理算子的一种可能的结构如下:
1 | (顶层)ProjectPhyOperator -> PredicatePhyOperator -> TableScanPhyOperator(底层) |
每一个算子所做的工作都是不同的,比如上面的示例中,最后一个算子将调用底层的一些写好的方法得到一个表中的每一行 Record,然后中间的算子会根据 where 后面的条件来决定要不要选取这行 Record,最前面的算子根据 select 和 from 之间的字段(field)来从 Predicate 算子选择的 Record 中再选择对应的字段。最终上层建筑从 ProjectPhyOperator 中拿到选择好的结果并输出。如下图所示:
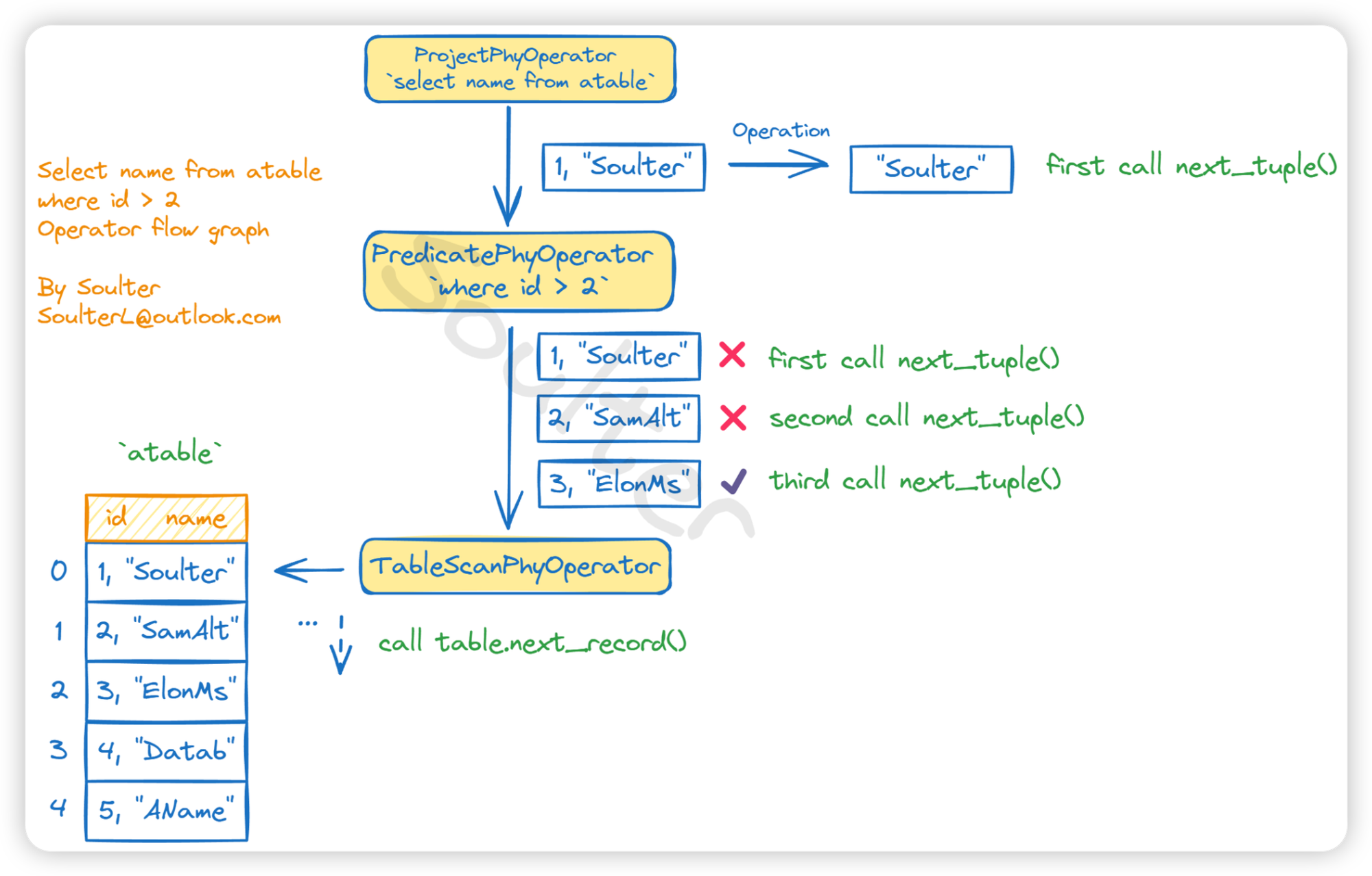
如你所见,经典数据库系统中的算子执行过程就像是一个个命运的齿轮转动,采用分而治之、层级化的思想,将数据一步步组合、筛选、排序,最终将结果呈现给用户。
Update 的实现过程记录
和 Delete 操作类似,当我们写好语法树和 Statement 之后,我们单独新建一个 Update 的逻辑算子和物理算子,将前一步操作得到的目的 Table、FieldMeta[]、Value[] 传递给这两个算子。逻辑算子内暂时不做任何操作。
- FieldMeta 即字段元数据,存储了一个表中某个字段的元数据,如类型、偏移量、长度等。
- Value 即一个确切的值,存储了 Value 类型、具体的值等。
1 | // |
在物理算子内(也就是真正开始执行获取数据的时候),我们需要从 Predicate(过滤) 算子中取出 Tuple,然后将其转换为 Record 类型,再调用底层的 UpdateTuple() 函数来进行更新(需要自己实现)。
上面没有提到复杂的合法性检测。我们需要在生成 Statement 时对 SQL 进行合法性检测:
- 检查 Table 是否存在;
- 检查 SET 部分指定的字段名是否存在于指定的 Table 中;
- 检查要更新的字段的值的类型是否符合字段类型(还要注意类型的隐式转换哦!)
- …
隐式类型转换
在 MySQL 中,是支持针对字段和值的隐式类型转换的。例如
- int cast to float (或者相反)
- chars cast to int (或者相反)
- chars cast to float (或者相反)
部分转换过程如下(篇幅限制,可能会精简一些不必要的内容)
1 | // 字段类型检查 |
诶,聪明的同学可能注意到了,如果是 chars 类型转 int 或 float 类型,是不是需要特别处理一些东西呢?
是的,但是如果你之前没有了解过 MySQL,那么你一定想不到针对这种类型的处理有多“智能”。让我们来看:
- 非数字字符不包括小数点。
- 当 char* 中遇到第一个非数字字符时,直接返回。若第一个就是非数字字符,那么返回 0。
- 当遇到数字字符时,和前面的数字字符组装形成新的值。
- 当遇到小数点时,开始加上小数部分。
下面我们看底层 Table、File、Page 的 UpdateTuple() 的过程,这里不考虑任何锁和并发的情况。
在获得 Record 之后,我们获取其中的 RID (记录的 ID ),在 File 级(一个 Table 对应一个或者多个 File)下,我们根据 RID 获得这个记录所在的页号,并调用 Page 级的 UpdateTuple() 函数。
一个 File下会存多个 Page,一个 Page 下会存多个 Record。Page 级下,我们预先在 Page 的元数据(我们存在了 Page 的头部,紧挨着 Page 头的地方)中存放这个 Page 的空间使用情况的位图 BitMap,一个 Record 对应 BitMap 中的一个 bit。通过 RID 中的 slot_num 来检查这个Record是否曾被删除。
1 | Bitmap bitmap(bitmap_, page_header_->record_capacity); |
实现数据库和实现操作系统的共同之处。学习过操作系统的初学者可能会恍然大悟,这不就跟早期(或者是现在)文件系统的实现大同小异吗!我们在设计文件系统的时候也会使用 BitMap 来记录哪一个 inode block 是否已用。
然后我们根据 RID 中的slot_num 找到这个page中指定的记录的数据,这个数据是 const char* 类型的。
1 | char *record_data = get_record_data(rid->slot_num); // 获取原先记录的数据首地址 |
通过 FieldMeta 中的偏移量和长度确定要修改的是 char* 值的哪一个地方,然后使用 memcpy()函数将 Value 中的内容复制到这个地方。
如果实现了索引,我们还需要更新索引,这里我们直接先把索引中旧 Record 对应的 Key 对应的 Node 删除,再添加一个新的 Node。
要注意的是,这只是最简单的数据库系统,其 Record 的长度是不可变的。在可变 Record 长度的 DBMS 下,这里的设计难度会大幅增加。
🚧 施工中 🚧